Reliability and Security of Deep Neural Networks ¶
 |  |  |
$\color{blue}{\text{Masoud Daneshtalab:}}$ Professor at Mälardalen University and TalTech¶
$\color{blue}{\text{Seyedhamidreza Mousavi:}}$ PhD student at Malardalan University¶
$\color{blue}{\text{Mohammad Hassan Ahmadilivani (Mojtaba):}}$ Postdoctoral researcher at TalTech University¶
 |  |  |
$\color{blue}{\text{Email:}}$ masoud.daneshtalab@mdu.se, seyedhamidreza.mousavi@mdu.se, mohammad.ahmadilivani@taltech.ee¶
 |  |
Reliability and security threats to machine learning-based systems¶

We are going to focus on two threats:
- Reliability issues (Hardware Faults) RReLU Framework
- Adversarial input perturbation ProARD Framework
First Part: Reliable ReLU Toolbox (RReLU) To Enhance Resilience of DNNs¶
What is a Deep Neural Network?¶

The application of DNNs: Object Detection¶
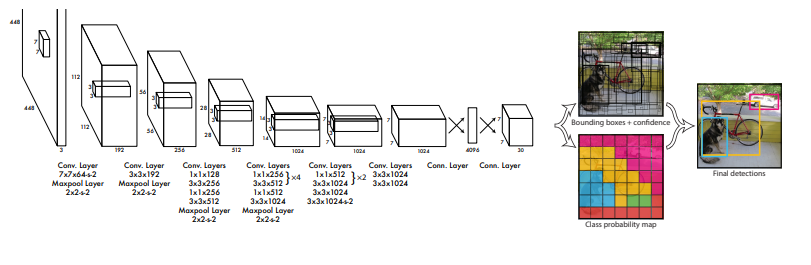
What is the Soft-errors problem?¶


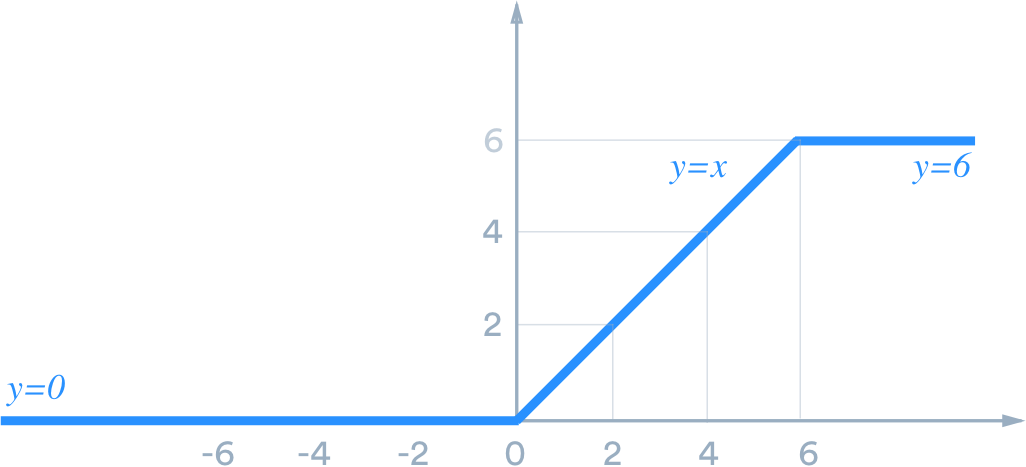
❓ What is the issue with ReLU?¶


✅ What is the solution?¶
❓How can we find the bound value for each ReLU activation function?
❓If the output activation is higher than bound, what should we do?
❓IS there any real situation that changed the activation value a lot?
❓Do we need to find one bound value for each layer or neuron?

Floating-Point Number¶

Activation Restriction Methods:¶
Bounded ReLU activation functions:

Algorithm for finding the bounds:
- Ranger used the calibration method in a layer-wise way.
- FT-ClipAct used a heuristic method based on fault-injection in a layer-wise manner.
- FitAct leveraged an optimisation-based method in a neuron-wise mode.
- ProAct used a Hybrid activation function (neuron-wise and layer-wise) and progressive training
ProAct provide an Open-Source Framework for all the Methods (RReLU)¶
It includes implementations of the following algorithms:

FitAct:¶

ProAct:¶

Instructions to use RReLU framework¶
Install Packages and Clone the RReLU Github Repository¶
!pip install fxpmath
!git clone https://github.com/hamidmousavi0/reliable-relu-toolbox.git
%cd reliable-relu-toolbox/
Collecting fxpmath
Downloading fxpmath-0.4.9.tar.gz (51 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/51.4 kB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 51.4/51.4 kB 2.2 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Requirement already satisfied: numpy in /usr/local/lib/python3.11/dist-packages (from fxpmath) (2.0.2)
Building wheels for collected packages: fxpmath
Building wheel for fxpmath (setup.py) ... done
Created wheel for fxpmath: filename=fxpmath-0.4.9-py3-none-any.whl size=35224 sha256=b2c920a21f6085ec3698efa90f2ade59794f81695dcaf2ccb902f01b0ae0ff92
Stored in directory: /root/.cache/pip/wheels/4a/75/f7/65a895cb07af2c0c9590a063373ade5b7215f26198c3704574
Successfully built fxpmath
Installing collected packages: fxpmath
Successfully installed fxpmath-0.4.9
Cloning into 'reliable-relu-toolbox'...
remote: Enumerating objects: 182, done.
remote: Counting objects: 100% (141/141), done.
remote: Compressing objects: 100% (111/111), done.
remote: Total 182 (delta 84), reused 54 (delta 29), pack-reused 41 (from 2)
Receiving objects: 100% (182/182), 6.94 MiB | 8.01 MiB/s, done.
Resolving deltas: 100% (86/86), done.
/content/reliable-relu-toolbox
Build Data Loader¶
First, we need to create the Dataset
from rrelu.setup import build_data_loader
data_loader_dict, n_classes = build_data_loader(dataset='cifar10',
batch_size=128, image_size=32)
import matplotlib.pyplot as plt
# Get the first batch from the training data loader
images, labels = next(iter(data_loader_dict['train']))
# Get the class names for CIFAR-10
# This assumes CIFAR-10 is used as specified in the previous cell
class_names = ['airplane', 'automobile', 'bird',
'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
# plt.figure(figsize=(10,10))
# for i in range(25):
# plt.subplot(5,5,i+1)
# plt.xticks([])
# plt.yticks([])
# plt.grid(False)
# # Transpose the image tensor to be in HxWxC format for plotting
# plt.imshow(images[i].permute(1, 2, 0))
# # The CIFAR10 labels are indices, so we use the class_names list
# plt.xlabel(class_names[labels[i].item()])
# plt.show()
100%|██████████| 170M/170M [00:13<00:00, 13.0MB/s] /usr/local/lib/python3.11/dist-packages/torch/utils/data/dataloader.py:624: UserWarning: This DataLoader will create 8 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary. warnings.warn(
Build Model¶
Our tool support pre-trained models on CIFAR-10, CIFAR-100, and ImageNet Dataset
Cifar-10 and Cifar-100 supported models:
- resnet20, resnet32, resnet44, resnet56
- vgg11_bn, vgg13_bn, vgg16_bn, vgg19-bn
- mobilenetv2_x0_5, mobilenetv2_x0_75
- shufflenetv2_x1_5
ImageNet supported Models:
- All the models in the PyTorch-hub
from rrelu.setup import build_model
model = build_model(name='resnet20',dataset='cifar10',
n_classes=n_classes)
print(model)
Downloading: "https://github.com/chenyaofo/pytorch-cifar-models/releases/download/resnet/cifar10_resnet20-4118986f.pt" to /root/.cache/torch/hub/checkpoints/cifar10_resnet20-4118986f.pt 100%|██████████| 1.09M/1.09M [00:00<00:00, 60.5MB/s]
CifarResNet(
(conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
)
(1): BasicBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
)
(2): BasicBlock(
(conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(16, 32, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
)
(2): BasicBlock(
(conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=64, out_features=10, bias=True)
)
Evaluate the original Model with ReLU activation function¶
from metrics import eval_,eval
print(eval_(model,data_loader_dict,'cuda'))
Eval: 100%|██████████| 79/79 [00:04<00:00, 16.54it/s, loss=0.282, top1=92.6, top5=99.8, #samples=1e+4, batch_size=16, img_size=32]
{'val_top1': 92.5999984741211, 'val_top5': 99.80999755859375, 'val_loss': 0.28152209520339966}
Convert Floating-Point weight values to the Fixed-Point¶
import torch
from fxpmath import Fxp
with torch.no_grad():
for name, param in model.named_parameters():
if param is not None:
param.copy_(torch.tensor(Fxp(param.clone().cpu().numpy(),
True, n_word=32, n_frac=16, n_int=15).get_val(),
dtype=torch.float32,device='cpu'))
Evaluate the Fixed-Point Model¶
print(eval_(model, data_loader_dict,'cuda'))
Eval: 100%|██████████| 79/79 [00:03<00:00, 21.38it/s, loss=0.281, top1=92.6, top5=99.8, #samples=1e+4, batch_size=16, img_size=32]
{'val_top1': 92.58999633789062, 'val_top5': 99.80999755859375, 'val_loss': 0.28144311904907227}
Evaluating Reliability of the model¶
from metrics import eval_fault_
print(eval_fault_(model, data_loader_dict,
1e-6, bitflip='fixed',iterations=5,device='cuda'))
============================ PYTORCHFI INIT SUMMARY ==============================
Layer types allowing injections:
----------------------------------------------------------------------------------
- Conv2d
- Linear
- Relu_bound
Model Info:
----------------------------------------------------------------------------------
- Shape of input into the model: (3 32 32 )
- Batch Size: 128
- CUDA Enabled: True
Layer Info:
----------------------------------------------------------------------------------
Layer # Layer type Dimensions Weight Shape Output Shape Bias Shape
----------------------------------------------------------------------------------
0 Conv2d 4 [16, 3, 3, 3] [1, 16, 32, 32] [None]
1 Conv2d 4 [16, 16, 3, 3] [1, 16, 32, 32] [None]
2 Conv2d 4 [16, 16, 3, 3] [1, 16, 32, 32] [None]
3 Conv2d 4 [16, 16, 3, 3] [1, 16, 32, 32] [None]
4 Conv2d 4 [16, 16, 3, 3] [1, 16, 32, 32] [None]
5 Conv2d 4 [16, 16, 3, 3] [1, 16, 32, 32] [None]
6 Conv2d 4 [16, 16, 3, 3] [1, 16, 32, 32] [None]
7 Conv2d 4 [32, 16, 3, 3] [1, 32, 16, 16] [None]
8 Conv2d 4 [32, 32, 3, 3] [1, 32, 16, 16] [None]
9 Conv2d 4 [32, 16, 1, 1] [1, 32, 16, 16] [None]
10 Conv2d 4 [32, 32, 3, 3] [1, 32, 16, 16] [None]
11 Conv2d 4 [32, 32, 3, 3] [1, 32, 16, 16] [None]
12 Conv2d 4 [32, 32, 3, 3] [1, 32, 16, 16] [None]
13 Conv2d 4 [32, 32, 3, 3] [1, 32, 16, 16] [None]
14 Conv2d 4 [64, 32, 3, 3] [1, 64, 8, 8] [None]
15 Conv2d 4 [64, 64, 3, 3] [1, 64, 8, 8] [None]
16 Conv2d 4 [64, 32, 1, 1] [1, 64, 8, 8] [None]
17 Conv2d 4 [64, 64, 3, 3] [1, 64, 8, 8] [None]
18 Conv2d 4 [64, 64, 3, 3] [1, 64, 8, 8] [None]
19 Conv2d 4 [64, 64, 3, 3] [1, 64, 8, 8] [None]
20 Conv2d 4 [64, 64, 3, 3] [1, 64, 8, 8] [None]
21 Linear 2 [10, 64] [1, 10] [10]
==================================================================================
Eval: 100%|██████████| 5/5 [00:20<00:00, 4.17s/it, loss=7.91e+4, top1=56.3, top5=79.9, #samples=5e+4, batch_size=16, img_size=32, fault_rate=1e-6]
{'val_top1': 56.26199722290039, 'val_top5': 79.9000015258789, 'val_loss': 79125.90625, 'fault_rate': 1e-06}
Build the model with Reliable ReLU¶
from rrelu.setup import replace_act
from metrics import eval_fault_
model = replace_act(model, 'proact', 'proact', data_loader_dict,
'layer', 'fixed',False ,'cifar10',is_root=True,device='cuda')
print(eval_fault_(model, data_loader_dict, 1e-6,
bitflip='fixed',iterations=5,device='cuda'))
Eval: 100%|██████████| 79/79 [00:02<00:00, 26.38it/s, loss=0.282, top1=92.6, top5=99.8, #samples=1e+4, batch_size=16, img_size=32]
92.57999420166016 the best accuracy is :92.57999420166016 layer3.2.relu2.bounds_param 4e-05
Train Epoch #1: 36%|███▋ | 142/390 [00:11<00:20, 12.11it/s, loss=0.0571, top1=99.6, batch_size=128, img_size=32, lr=0.01, data_time=0.00646]
--------------------------------------------------------------------------- KeyboardInterrupt Traceback (most recent call last) <ipython-input-8-795bea707d36> in <cell line: 0>() 1 from rrelu.setup import replace_act 2 from metrics import eval_fault_ ----> 3 model = replace_act(model, 'zero', 'proact', data_loader_dict, 4 'layer', 'fixed',False ,'cifar10',is_root=True,device='cuda') 5 print(eval_fault_(model, data_loader_dict, 1e-6, /content/reliable-relu-toolbox/rrelu/setup.py in replace_act(model, name_relu_bound, name_serach_bound, data_loader, bound_type, bitflip, pretrained, dataset, is_root, device) 385 tresh[key] = torch.min(tresh[key]) 386 else: --> 387 bounds,tresh,alpha = find_bounds(copy.deepcopy(model),data_loader,name_serach_bound,bound_type,bitflip,is_root,device=device) 388 model = replace_act_all(model,replace_act_dict[name_relu_bound],bounds,tresh,alpha,prefix='',device=device) 389 return model /content/reliable-relu-toolbox/rrelu/setup.py in find_bounds(model, data_loader, name, bound_type, bitflip, is_root, device) 329 'proact' : proact_bounds 330 } --> 331 return search_bounds_dict[name](model,data_loader,bound_type=bound_type,bitflip=bitflip,is_root = is_root,device=device) 332 333 def replace_act_all(model:nn.Module,relu_bound,bounds,tresh,alpha=None, prefix='',device='cuda')->nn.Module: /content/reliable-relu-toolbox/rrelu/search_bound/proact.py in proact_bounds(model, train_loader, bound_type, bitflip, is_root, device) 161 162 weight_decay_list =[4e-5,4e-6,4e-7,4e-8,4e-9,4e-10,4e-11,4e-12,4e-13,4e-14,4e-15] --> 163 model = train(model=model,original_model=original_model,data_provider=train_loader,weight_decay_list=weight_decay_list,bound_type=bound_type,bitflip=bitflip,is_root=is_root,device=device) 164 model.load_state_dict(torch.load("temp_{}_{}_{}.pth".format(bound_type,bitflip,original_model.__class__.__name__))) 165 for name, param in model.named_parameters(): /content/reliable-relu-toolbox/rrelu/search_bound/proact.py in train(model, original_model, data_provider, weight_decay_list, base_lr, warmup_epochs, n_epochs, treshold, bound_type, bitflip, is_root, device) 288 ): 289 --> 290 train_info_dict = train_one_epoch( 291 model, 292 original_model, /content/reliable-relu-toolbox/rrelu/search_bound/proact.py in train_one_epoch(model, original_model, data_provider, is_root, epoch, optimizer, criterion, lr_scheduler, device) 368 nat_logits,teacher_logits 369 ) --> 370 nat_logits = model(images) 371 loss = criterion(nat_logits,labels) + kd_loss # + wd * l2_bounds #+ 0.1 * k_loss # 372 loss.backward() /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs) 1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc] 1738 else: -> 1739 return self._call_impl(*args, **kwargs) 1740 1741 # torchrec tests the code consistency with the following code /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1748 or _global_backward_pre_hooks or _global_backward_hooks 1749 or _global_forward_hooks or _global_forward_pre_hooks): -> 1750 return forward_call(*args, **kwargs) 1751 1752 result = None /content/reliable-relu-toolbox/rrelu/models_cifar/resnet.py in forward(self, x) 156 x = block(x) 157 for i, block in enumerate(self.layer2): --> 158 x = block(x) 159 for i, block in enumerate(self.layer3): 160 x = block(x) /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs) 1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc] 1738 else: -> 1739 return self._call_impl(*args, **kwargs) 1740 1741 # torchrec tests the code consistency with the following code /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1748 or _global_backward_pre_hooks or _global_backward_hooks 1749 or _global_forward_hooks or _global_forward_pre_hooks): -> 1750 return forward_call(*args, **kwargs) 1751 1752 result = None /content/reliable-relu-toolbox/rrelu/models_cifar/resnet.py in forward(self, x) 95 96 out = self.conv2(out) ---> 97 out = self.bn2(out) 98 99 if self.downsample is not None: /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs) 1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc] 1738 else: -> 1739 return self._call_impl(*args, **kwargs) 1740 1741 # torchrec tests the code consistency with the following code /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1748 or _global_backward_pre_hooks or _global_backward_hooks 1749 or _global_forward_hooks or _global_forward_pre_hooks): -> 1750 return forward_call(*args, **kwargs) 1751 1752 result = None /usr/local/lib/python3.11/dist-packages/torch/nn/modules/batchnorm.py in forward(self, input) 171 # TODO: if statement only here to tell the jit to skip emitting this when it is None 172 if self.num_batches_tracked is not None: # type: ignore[has-type] --> 173 self.num_batches_tracked.add_(1) # type: ignore[has-type] 174 if self.momentum is None: # use cumulative moving average 175 exponential_average_factor = 1.0 / float(self.num_batches_tracked) KeyboardInterrupt:
# rm -r reliable-relu-toolbox/

Second Part: ProARD: Progressive Adversarial Robustness Distillation: Provide Wide Range of Robust Students¶
How about the perturbation in the input data? How can we defend against this type of attacks?¶

The state-of-the-art method is Adversarial Training.¶
The state-of-the-art methods are:
- TRADES: Theoretically Principled Trade-off between Robustness and Accuracy
- ARD: Adversarial Robustness Distillation: Use a Robust Teacher Network to train the student's networks. (What is the issue?)

Is it possible to train a single robust supernetwork and extract multiple robust subnetworks from it, each tailored to different resource-constrained devices—without requiring retraining?¶
How should we train this super-network?¶
- Randomly sample subnetworks from the supernetwork, train them independently, and return their updates to the supernetwork using weight sharing.
- Does it work?
First step: Making Super Dynamic Network:¶

If we trained the multiple subnetworks inside a supernetwork by randomly subsampling, what would be their accuracy and robustness?¶

We propose Progressive Adversarial Robustness Distillation (ProARD).
Enabling the efficient one-time training of a dynamic network that supports a diverse range of accurate and robust student networks without requiring retraining.
ProARD: Progressive Adversarial Robustness Distillation: Provide Wide Range of Robust Students¶

Results¶

!git clone https://github.com/hamidmousavi0/Robust_OFA.git
Cloning into 'Robust_OFA'... remote: Enumerating objects: 290, done. remote: Counting objects: 100% (290/290), done. remote: Compressing objects: 100% (222/222), done. remote: Total 290 (delta 51), reused 260 (delta 47), pack-reused 0 (from 0) Receiving objects: 100% (290/290), 27.92 MiB | 20.82 MiB/s, done. Resolving deltas: 100% (51/51), done.
!pip install git+https://github.com/jeromerony/adversarial-library
Collecting git+https://github.com/jeromerony/adversarial-library
Cloning https://github.com/jeromerony/adversarial-library to /tmp/pip-req-build-9zgkyl1r
Running command git clone --filter=blob:none --quiet https://github.com/jeromerony/adversarial-library /tmp/pip-req-build-9zgkyl1r
Resolved https://github.com/jeromerony/adversarial-library to commit 4ca9b77bb6c909d47e161ced0e257c6003fb4116
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Requirement already satisfied: torch>=1.8.0 in /usr/local/lib/python3.11/dist-packages (from adv-lib==0.2.3) (2.6.0+cu124)
Requirement already satisfied: torchvision>=0.9.0 in /usr/local/lib/python3.11/dist-packages (from adv-lib==0.2.3) (0.21.0+cu124)
Requirement already satisfied: tqdm>=4.48.0 in /usr/local/lib/python3.11/dist-packages (from adv-lib==0.2.3) (4.67.1)
Collecting visdom>=0.1.8 (from adv-lib==0.2.3)
Downloading visdom-0.2.4.tar.gz (1.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.4/1.4 MB 29.8 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Requirement already satisfied: filelock in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (3.18.0)
Requirement already satisfied: typing-extensions>=4.10.0 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (4.13.2)
Requirement already satisfied: networkx in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (3.4.2)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (3.1.6)
Requirement already satisfied: fsspec in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (2025.3.2)
Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (12.4.127)
Requirement already satisfied: nvidia-cuda-runtime-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (12.4.127)
Requirement already satisfied: nvidia-cuda-cupti-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (12.4.127)
Requirement already satisfied: nvidia-cudnn-cu12==9.1.0.70 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (9.1.0.70)
Requirement already satisfied: nvidia-cublas-cu12==12.4.5.8 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (12.4.5.8)
Requirement already satisfied: nvidia-cufft-cu12==11.2.1.3 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (11.2.1.3)
Requirement already satisfied: nvidia-curand-cu12==10.3.5.147 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (10.3.5.147)
Requirement already satisfied: nvidia-cusolver-cu12==11.6.1.9 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (11.6.1.9)
Requirement already satisfied: nvidia-cusparse-cu12==12.3.1.170 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (12.3.1.170)
Requirement already satisfied: nvidia-cusparselt-cu12==0.6.2 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (0.6.2)
Requirement already satisfied: nvidia-nccl-cu12==2.21.5 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (2.21.5)
Requirement already satisfied: nvidia-nvtx-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (12.4.127)
Requirement already satisfied: nvidia-nvjitlink-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (12.4.127)
Requirement already satisfied: triton==3.2.0 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (3.2.0)
Requirement already satisfied: sympy==1.13.1 in /usr/local/lib/python3.11/dist-packages (from torch>=1.8.0->adv-lib==0.2.3) (1.13.1)
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /usr/local/lib/python3.11/dist-packages (from sympy==1.13.1->torch>=1.8.0->adv-lib==0.2.3) (1.3.0)
Requirement already satisfied: numpy in /usr/local/lib/python3.11/dist-packages (from torchvision>=0.9.0->adv-lib==0.2.3) (2.0.2)
Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.11/dist-packages (from torchvision>=0.9.0->adv-lib==0.2.3) (11.2.1)
Requirement already satisfied: scipy in /usr/local/lib/python3.11/dist-packages (from visdom>=0.1.8->adv-lib==0.2.3) (1.15.3)
Requirement already satisfied: requests in /usr/local/lib/python3.11/dist-packages (from visdom>=0.1.8->adv-lib==0.2.3) (2.32.3)
Requirement already satisfied: tornado in /usr/local/lib/python3.11/dist-packages (from visdom>=0.1.8->adv-lib==0.2.3) (6.4.2)
Requirement already satisfied: six in /usr/local/lib/python3.11/dist-packages (from visdom>=0.1.8->adv-lib==0.2.3) (1.17.0)
Requirement already satisfied: jsonpatch in /usr/local/lib/python3.11/dist-packages (from visdom>=0.1.8->adv-lib==0.2.3) (1.33)
Requirement already satisfied: websocket-client in /usr/local/lib/python3.11/dist-packages (from visdom>=0.1.8->adv-lib==0.2.3) (1.8.0)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.11/dist-packages (from jinja2->torch>=1.8.0->adv-lib==0.2.3) (3.0.2)
Requirement already satisfied: jsonpointer>=1.9 in /usr/local/lib/python3.11/dist-packages (from jsonpatch->visdom>=0.1.8->adv-lib==0.2.3) (3.0.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.11/dist-packages (from requests->visdom>=0.1.8->adv-lib==0.2.3) (3.4.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.11/dist-packages (from requests->visdom>=0.1.8->adv-lib==0.2.3) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.11/dist-packages (from requests->visdom>=0.1.8->adv-lib==0.2.3) (2.4.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.11/dist-packages (from requests->visdom>=0.1.8->adv-lib==0.2.3) (2025.4.26)
Building wheels for collected packages: adv-lib, visdom
Building wheel for adv-lib (pyproject.toml) ... done
Created wheel for adv-lib: filename=adv_lib-0.2.3-py3-none-any.whl size=80902 sha256=cbb9a0bdb8a4da5192854d847f07d77422568d7db9b8f37e8265206f312557bd
Stored in directory: /tmp/pip-ephem-wheel-cache-kyih6hm2/wheels/05/30/19/2a22b538277b159dbb3b554f29a1e8d23fc140c3d09b663dc1
Building wheel for visdom (setup.py) ... done
Created wheel for visdom: filename=visdom-0.2.4-py3-none-any.whl size=1408195 sha256=db9a3f4ff91cfca70ed06a65261fb74b2bf2961ad509ec1c1183166a6b96a0df
Stored in directory: /root/.cache/pip/wheels/fa/a4/bb/2be445c295d88a74f9c0a4232f04860ca489a5c7c57eb959d9
Successfully built adv-lib visdom
Installing collected packages: visdom, adv-lib
Successfully installed adv-lib-0.2.3 visdom-0.2.4
!pip install adversarial-robustness-toolbox
Collecting adversarial-robustness-toolbox Downloading adversarial_robustness_toolbox-1.19.1-py3-none-any.whl.metadata (11 kB) Requirement already satisfied: numpy>=1.18.0 in /usr/local/lib/python3.11/dist-packages (from adversarial-robustness-toolbox) (2.0.2) Requirement already satisfied: scipy>=1.4.1 in /usr/local/lib/python3.11/dist-packages (from adversarial-robustness-toolbox) (1.15.3) Requirement already satisfied: scikit-learn>=0.22.2 in /usr/local/lib/python3.11/dist-packages (from adversarial-robustness-toolbox) (1.6.1) Requirement already satisfied: six in /usr/local/lib/python3.11/dist-packages (from adversarial-robustness-toolbox) (1.17.0) Requirement already satisfied: setuptools in /usr/local/lib/python3.11/dist-packages (from adversarial-robustness-toolbox) (75.2.0) Requirement already satisfied: tqdm in /usr/local/lib/python3.11/dist-packages (from adversarial-robustness-toolbox) (4.67.1) Requirement already satisfied: joblib>=1.2.0 in /usr/local/lib/python3.11/dist-packages (from scikit-learn>=0.22.2->adversarial-robustness-toolbox) (1.5.0) Requirement already satisfied: threadpoolctl>=3.1.0 in /usr/local/lib/python3.11/dist-packages (from scikit-learn>=0.22.2->adversarial-robustness-toolbox) (3.6.0) Downloading adversarial_robustness_toolbox-1.19.1-py3-none-any.whl (1.7 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.7/1.7 MB 25.7 MB/s eta 0:00:00 Installing collected packages: adversarial-robustness-toolbox Successfully installed adversarial-robustness-toolbox-1.19.1
!pip install torchprofile
!pip install torchpack
Collecting torchprofile Downloading torchprofile-0.0.4-py3-none-any.whl.metadata (303 bytes) Requirement already satisfied: numpy>=1.14 in /usr/local/lib/python3.11/dist-packages (from torchprofile) (2.0.2) Requirement already satisfied: torch>=1.4 in /usr/local/lib/python3.11/dist-packages (from torchprofile) (2.6.0+cu124) Requirement already satisfied: torchvision>=0.4 in /usr/local/lib/python3.11/dist-packages (from torchprofile) (0.21.0+cu124) Requirement already satisfied: filelock in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (3.18.0) Requirement already satisfied: typing-extensions>=4.10.0 in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (4.13.2) Requirement already satisfied: networkx in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (3.4.2) Requirement already satisfied: jinja2 in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (3.1.6) Requirement already satisfied: fsspec in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (2025.3.2) Collecting nvidia-cuda-nvrtc-cu12==12.4.127 (from torch>=1.4->torchprofile) Downloading nvidia_cuda_nvrtc_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-cuda-runtime-cu12==12.4.127 (from torch>=1.4->torchprofile) Downloading nvidia_cuda_runtime_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-cuda-cupti-cu12==12.4.127 (from torch>=1.4->torchprofile) Downloading nvidia_cuda_cupti_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB) Collecting nvidia-cudnn-cu12==9.1.0.70 (from torch>=1.4->torchprofile) Downloading nvidia_cudnn_cu12-9.1.0.70-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB) Collecting nvidia-cublas-cu12==12.4.5.8 (from torch>=1.4->torchprofile) Downloading nvidia_cublas_cu12-12.4.5.8-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-cufft-cu12==11.2.1.3 (from torch>=1.4->torchprofile) Downloading nvidia_cufft_cu12-11.2.1.3-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-curand-cu12==10.3.5.147 (from torch>=1.4->torchprofile) Downloading nvidia_curand_cu12-10.3.5.147-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Collecting nvidia-cusolver-cu12==11.6.1.9 (from torch>=1.4->torchprofile) Downloading nvidia_cusolver_cu12-11.6.1.9-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB) Collecting nvidia-cusparse-cu12==12.3.1.170 (from torch>=1.4->torchprofile) Downloading nvidia_cusparse_cu12-12.3.1.170-py3-none-manylinux2014_x86_64.whl.metadata (1.6 kB) Requirement already satisfied: nvidia-cusparselt-cu12==0.6.2 in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (0.6.2) Requirement already satisfied: nvidia-nccl-cu12==2.21.5 in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (2.21.5) Requirement already satisfied: nvidia-nvtx-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (12.4.127) Collecting nvidia-nvjitlink-cu12==12.4.127 (from torch>=1.4->torchprofile) Downloading nvidia_nvjitlink_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl.metadata (1.5 kB) Requirement already satisfied: triton==3.2.0 in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (3.2.0) Requirement already satisfied: sympy==1.13.1 in /usr/local/lib/python3.11/dist-packages (from torch>=1.4->torchprofile) (1.13.1) Requirement already satisfied: mpmath<1.4,>=1.1.0 in /usr/local/lib/python3.11/dist-packages (from sympy==1.13.1->torch>=1.4->torchprofile) (1.3.0) Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.11/dist-packages (from torchvision>=0.4->torchprofile) (11.2.1) Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.11/dist-packages (from jinja2->torch>=1.4->torchprofile) (3.0.2) Downloading torchprofile-0.0.4-py3-none-any.whl (7.7 kB) Downloading nvidia_cublas_cu12-12.4.5.8-py3-none-manylinux2014_x86_64.whl (363.4 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 363.4/363.4 MB 4.0 MB/s eta 0:00:00 Downloading nvidia_cuda_cupti_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (13.8 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.8/13.8 MB 65.6 MB/s eta 0:00:00 Downloading nvidia_cuda_nvrtc_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (24.6 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24.6/24.6 MB 35.7 MB/s eta 0:00:00 Downloading nvidia_cuda_runtime_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (883 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 883.7/883.7 kB 53.4 MB/s eta 0:00:00 Downloading nvidia_cudnn_cu12-9.1.0.70-py3-none-manylinux2014_x86_64.whl (664.8 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 664.8/664.8 MB 2.0 MB/s eta 0:00:00 Downloading nvidia_cufft_cu12-11.2.1.3-py3-none-manylinux2014_x86_64.whl (211.5 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 211.5/211.5 MB 5.9 MB/s eta 0:00:00 Downloading nvidia_curand_cu12-10.3.5.147-py3-none-manylinux2014_x86_64.whl (56.3 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 56.3/56.3 MB 13.2 MB/s eta 0:00:00 Downloading nvidia_cusolver_cu12-11.6.1.9-py3-none-manylinux2014_x86_64.whl (127.9 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 127.9/127.9 MB 7.4 MB/s eta 0:00:00 Downloading nvidia_cusparse_cu12-12.3.1.170-py3-none-manylinux2014_x86_64.whl (207.5 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 207.5/207.5 MB 5.3 MB/s eta 0:00:00 Downloading nvidia_nvjitlink_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (21.1 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 21.1/21.1 MB 102.8 MB/s eta 0:00:00 Installing collected packages: nvidia-nvjitlink-cu12, nvidia-curand-cu12, nvidia-cufft-cu12, nvidia-cuda-runtime-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-cupti-cu12, nvidia-cublas-cu12, nvidia-cusparse-cu12, nvidia-cudnn-cu12, nvidia-cusolver-cu12, torchprofile Attempting uninstall: nvidia-nvjitlink-cu12 Found existing installation: nvidia-nvjitlink-cu12 12.5.82 Uninstalling nvidia-nvjitlink-cu12-12.5.82: Successfully uninstalled nvidia-nvjitlink-cu12-12.5.82 Attempting uninstall: nvidia-curand-cu12 Found existing installation: nvidia-curand-cu12 10.3.6.82 Uninstalling nvidia-curand-cu12-10.3.6.82: Successfully uninstalled nvidia-curand-cu12-10.3.6.82 Attempting uninstall: nvidia-cufft-cu12 Found existing installation: nvidia-cufft-cu12 11.2.3.61 Uninstalling nvidia-cufft-cu12-11.2.3.61: Successfully uninstalled nvidia-cufft-cu12-11.2.3.61 Attempting uninstall: nvidia-cuda-runtime-cu12 Found existing installation: nvidia-cuda-runtime-cu12 12.5.82 Uninstalling nvidia-cuda-runtime-cu12-12.5.82: Successfully uninstalled nvidia-cuda-runtime-cu12-12.5.82 Attempting uninstall: nvidia-cuda-nvrtc-cu12 Found existing installation: nvidia-cuda-nvrtc-cu12 12.5.82 Uninstalling nvidia-cuda-nvrtc-cu12-12.5.82: Successfully uninstalled nvidia-cuda-nvrtc-cu12-12.5.82 Attempting uninstall: nvidia-cuda-cupti-cu12 Found existing installation: nvidia-cuda-cupti-cu12 12.5.82 Uninstalling nvidia-cuda-cupti-cu12-12.5.82: Successfully uninstalled nvidia-cuda-cupti-cu12-12.5.82 Attempting uninstall: nvidia-cublas-cu12 Found existing installation: nvidia-cublas-cu12 12.5.3.2 Uninstalling nvidia-cublas-cu12-12.5.3.2: Successfully uninstalled nvidia-cublas-cu12-12.5.3.2 Attempting uninstall: nvidia-cusparse-cu12 Found existing installation: nvidia-cusparse-cu12 12.5.1.3 Uninstalling nvidia-cusparse-cu12-12.5.1.3: Successfully uninstalled nvidia-cusparse-cu12-12.5.1.3 Attempting uninstall: nvidia-cudnn-cu12 Found existing installation: nvidia-cudnn-cu12 9.3.0.75 Uninstalling nvidia-cudnn-cu12-9.3.0.75: Successfully uninstalled nvidia-cudnn-cu12-9.3.0.75 Attempting uninstall: nvidia-cusolver-cu12 Found existing installation: nvidia-cusolver-cu12 11.6.3.83 Uninstalling nvidia-cusolver-cu12-11.6.3.83: Successfully uninstalled nvidia-cusolver-cu12-11.6.3.83 Successfully installed nvidia-cublas-cu12-12.4.5.8 nvidia-cuda-cupti-cu12-12.4.127 nvidia-cuda-nvrtc-cu12-12.4.127 nvidia-cuda-runtime-cu12-12.4.127 nvidia-cudnn-cu12-9.1.0.70 nvidia-cufft-cu12-11.2.1.3 nvidia-curand-cu12-10.3.5.147 nvidia-cusolver-cu12-11.6.1.9 nvidia-cusparse-cu12-12.3.1.170 nvidia-nvjitlink-cu12-12.4.127 torchprofile-0.0.4 Collecting torchpack Downloading torchpack-0.3.1-py3-none-any.whl.metadata (533 bytes) Requirement already satisfied: h5py in /usr/local/lib/python3.11/dist-packages (from torchpack) (3.13.0) Collecting loguru (from torchpack) Downloading loguru-0.7.3-py3-none-any.whl.metadata (22 kB) Collecting multimethod (from torchpack) Downloading multimethod-2.0-py3-none-any.whl.metadata (9.2 kB) Requirement already satisfied: numpy in /usr/local/lib/python3.11/dist-packages (from torchpack) (2.0.2) Requirement already satisfied: pyyaml in /usr/local/lib/python3.11/dist-packages (from torchpack) (6.0.2) Requirement already satisfied: scipy in /usr/local/lib/python3.11/dist-packages (from torchpack) (1.15.3) Requirement already satisfied: tensorboard in /usr/local/lib/python3.11/dist-packages (from torchpack) (2.18.0) Collecting tensorpack (from torchpack) Downloading tensorpack-0.11-py2.py3-none-any.whl.metadata (5.4 kB) Requirement already satisfied: toml in /usr/local/lib/python3.11/dist-packages (from torchpack) (0.10.2) Requirement already satisfied: torch>=1.5.0 in /usr/local/lib/python3.11/dist-packages (from torchpack) (2.6.0+cu124) Requirement already satisfied: torchvision in /usr/local/lib/python3.11/dist-packages (from torchpack) (0.21.0+cu124) Requirement already satisfied: tqdm in /usr/local/lib/python3.11/dist-packages (from torchpack) (4.67.1) Requirement already satisfied: filelock in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (3.18.0) Requirement already satisfied: typing-extensions>=4.10.0 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (4.13.2) Requirement already satisfied: networkx in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (3.4.2) Requirement already satisfied: jinja2 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (3.1.6) Requirement already satisfied: fsspec in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (2025.3.2) Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (12.4.127) Requirement already satisfied: nvidia-cuda-runtime-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (12.4.127) Requirement already satisfied: nvidia-cuda-cupti-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (12.4.127) Requirement already satisfied: nvidia-cudnn-cu12==9.1.0.70 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (9.1.0.70) Requirement already satisfied: nvidia-cublas-cu12==12.4.5.8 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (12.4.5.8) Requirement already satisfied: nvidia-cufft-cu12==11.2.1.3 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (11.2.1.3) Requirement already satisfied: nvidia-curand-cu12==10.3.5.147 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (10.3.5.147) Requirement already satisfied: nvidia-cusolver-cu12==11.6.1.9 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (11.6.1.9) Requirement already satisfied: nvidia-cusparse-cu12==12.3.1.170 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (12.3.1.170) Requirement already satisfied: nvidia-cusparselt-cu12==0.6.2 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (0.6.2) Requirement already satisfied: nvidia-nccl-cu12==2.21.5 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (2.21.5) Requirement already satisfied: nvidia-nvtx-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (12.4.127) Requirement already satisfied: nvidia-nvjitlink-cu12==12.4.127 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (12.4.127) Requirement already satisfied: triton==3.2.0 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (3.2.0) Requirement already satisfied: sympy==1.13.1 in /usr/local/lib/python3.11/dist-packages (from torch>=1.5.0->torchpack) (1.13.1) Requirement already satisfied: mpmath<1.4,>=1.1.0 in /usr/local/lib/python3.11/dist-packages (from sympy==1.13.1->torch>=1.5.0->torchpack) (1.3.0) Requirement already satisfied: absl-py>=0.4 in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (1.4.0) Requirement already satisfied: grpcio>=1.48.2 in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (1.71.0) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (3.8) Requirement already satisfied: packaging in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (24.2) Requirement already satisfied: protobuf!=4.24.0,>=3.19.6 in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (5.29.4) Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (75.2.0) Requirement already satisfied: six>1.9 in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (1.17.0) Requirement already satisfied: tensorboard-data-server<0.8.0,>=0.7.0 in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (0.7.2) Requirement already satisfied: werkzeug>=1.0.1 in /usr/local/lib/python3.11/dist-packages (from tensorboard->torchpack) (3.1.3) Requirement already satisfied: termcolor>=1.1 in /usr/local/lib/python3.11/dist-packages (from tensorpack->torchpack) (3.1.0) Requirement already satisfied: tabulate>=0.7.7 in /usr/local/lib/python3.11/dist-packages (from tensorpack->torchpack) (0.9.0) Requirement already satisfied: msgpack>=0.5.2 in /usr/local/lib/python3.11/dist-packages (from tensorpack->torchpack) (1.1.0) Collecting msgpack-numpy>=0.4.4.2 (from tensorpack->torchpack) Downloading msgpack_numpy-0.4.8-py2.py3-none-any.whl.metadata (5.0 kB) Requirement already satisfied: pyzmq>=16 in /usr/local/lib/python3.11/dist-packages (from tensorpack->torchpack) (24.0.1) Requirement already satisfied: psutil>=5 in /usr/local/lib/python3.11/dist-packages (from tensorpack->torchpack) (5.9.5) Requirement already satisfied: pillow!=8.3.*,>=5.3.0 in /usr/local/lib/python3.11/dist-packages (from torchvision->torchpack) (11.2.1) Requirement already satisfied: MarkupSafe>=2.1.1 in /usr/local/lib/python3.11/dist-packages (from werkzeug>=1.0.1->tensorboard->torchpack) (3.0.2) Downloading torchpack-0.3.1-py3-none-any.whl (34 kB) Downloading loguru-0.7.3-py3-none-any.whl (61 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 61.6/61.6 kB 6.2 MB/s eta 0:00:00 Downloading multimethod-2.0-py3-none-any.whl (9.8 kB) Downloading tensorpack-0.11-py2.py3-none-any.whl (296 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 296.3/296.3 kB 18.0 MB/s eta 0:00:00 Downloading msgpack_numpy-0.4.8-py2.py3-none-any.whl (6.9 kB) Installing collected packages: multimethod, msgpack-numpy, loguru, tensorpack, torchpack Successfully installed loguru-0.7.3 msgpack-numpy-0.4.8 multimethod-2.0 tensorpack-0.11 torchpack-0.3.1
!pip install git+https://github.com/fra31/auto-attack
Collecting git+https://github.com/fra31/auto-attack Cloning https://github.com/fra31/auto-attack to /tmp/pip-req-build-u0cfxiby Running command git clone --filter=blob:none --quiet https://github.com/fra31/auto-attack /tmp/pip-req-build-u0cfxiby Resolved https://github.com/fra31/auto-attack to commit a39220048b3c9f2cca9a4d3a54604793c68eca7e Preparing metadata (setup.py) ... done Building wheels for collected packages: autoattack Building wheel for autoattack (setup.py) ... done Created wheel for autoattack: filename=autoattack-0.1-py3-none-any.whl size=36228 sha256=220d3f69c648d8a5f5e53fcc35e1a7b6e1fca3527117b5e820474efc826caab7 Stored in directory: /tmp/pip-ephem-wheel-cache-nlf2_bps/wheels/e1/e8/28/65b2724d4c7740785979eb50bf5e1b3986ead22f6c32a87f8f Successfully built autoattack Installing collected packages: autoattack Successfully installed autoattack-0.1
cd Robust_OFA/
/content/Robust_OFA
import gdown
gdown.download("https://drive.google.com/uc?export=download&id=1Z7HdxG-Wwg54xQRcLZXSBNlxLvBDjduZ","model_best.pth.tar")
Downloading... From (original): https://drive.google.com/uc?export=download&id=1Z7HdxG-Wwg54xQRcLZXSBNlxLvBDjduZ From (redirected): https://drive.google.com/uc?export=download&id=1Z7HdxG-Wwg54xQRcLZXSBNlxLvBDjduZ&confirm=t&uuid=2eccd0a8-a32e-4d97-a74f-a304dd5b62fc To: /content/Robust_OFA/model_best.pth.tar 100%|██████████| 185M/185M [00:00<00:00, 210MB/s]
'model_best.pth.tar'
mv model_best.pth.tar exp/robust/cifar10/ResNet50/trades/width_depth2width_depth_width/phase2/checkpoint/
!python eval_ofa_net.py
exp/robust/cifar10/ResNet50/trades/width_depth2width_depth_width/phase2/checkpoint/model_best.pth.tar
ResNets_Cifar(
(input_stem): ModuleList(
(0): ConvLayer(
(conv): Conv2d(3, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(1): ConvLayer(
(conv): Conv2d(24, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
)
(blocks): ModuleList(
(0): ResNetBottleneckBlock(
(conv1): Sequential(
(conv): Conv2d(40, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv2): Sequential(
(conv): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv3): Sequential(
(conv): Conv2d(40, 168, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(168, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): Sequential(
(conv): Conv2d(40, 168, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(168, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(final_act): ReLU(inplace=True)
)
(1-2): 2 x ResNetBottleneckBlock(
(conv1): Sequential(
(conv): Conv2d(168, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv2): Sequential(
(conv): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv3): Sequential(
(conv): Conv2d(40, 168, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(168, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): IdentityLayer()
(final_act): ReLU(inplace=True)
)
(3): ResNetBottleneckBlock(
(conv1): Sequential(
(conv): Conv2d(168, 88, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(88, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv2): Sequential(
(conv): Conv2d(88, 88, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(88, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv3): Sequential(
(conv): Conv2d(88, 336, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): Sequential(
(conv): Conv2d(168, 336, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(final_act): ReLU(inplace=True)
)
(4-5): 2 x ResNetBottleneckBlock(
(conv1): Sequential(
(conv): Conv2d(336, 88, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(88, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv2): Sequential(
(conv): Conv2d(88, 88, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(88, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv3): Sequential(
(conv): Conv2d(88, 336, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): IdentityLayer()
(final_act): ReLU(inplace=True)
)
(6): ResNetBottleneckBlock(
(conv1): Sequential(
(conv): Conv2d(336, 168, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(168, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv2): Sequential(
(conv): Conv2d(168, 168, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(168, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv3): Sequential(
(conv): Conv2d(168, 664, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(664, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): Sequential(
(conv): Conv2d(336, 664, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(664, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(final_act): ReLU(inplace=True)
)
(7-10): 4 x ResNetBottleneckBlock(
(conv1): Sequential(
(conv): Conv2d(664, 168, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(168, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv2): Sequential(
(conv): Conv2d(168, 168, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(168, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv3): Sequential(
(conv): Conv2d(168, 664, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(664, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): IdentityLayer()
(final_act): ReLU(inplace=True)
)
(11): ResNetBottleneckBlock(
(conv1): Sequential(
(conv): Conv2d(664, 336, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv2): Sequential(
(conv): Conv2d(336, 336, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv3): Sequential(
(conv): Conv2d(336, 1328, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1328, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): Sequential(
(conv): Conv2d(664, 1328, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(1328, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(final_act): ReLU(inplace=True)
)
(12-13): 2 x ResNetBottleneckBlock(
(conv1): Sequential(
(conv): Conv2d(1328, 336, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv2): Sequential(
(conv): Conv2d(336, 336, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU(inplace=True)
)
(conv3): Sequential(
(conv): Conv2d(336, 1328, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1328, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): IdentityLayer()
(final_act): ReLU(inplace=True)
)
)
(global_avg_pool): MyGlobalAvgPool2d(keep_dim=False)
(classifier): LinearLayer(
(linear): Linear(in_features=1328, out_features=10, bias=True)
)
)
Total training params: 9.51M
Total FLOPs: 24733.27M
Test random subnet:
Validate Epoch #1 : 9% 55/625 [00:22<03:53, 2.44it/s, loss=1.83, top1=84.2, top5=98.6, robust1=49.4, robust5=94, img_size=32]
Traceback (most recent call last):
File "/content/Robust_OFA/eval_ofa_net.py", line 93, in <module>
loss, (top1, top5,robust1,robust5) = run_manager.validate(net=subnet,is_test=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/content/Robust_OFA/ofa/classification/run_manager/run_manager.py", line 272, in validate
images_adv,_ = eval_attack.perturb(images, labels)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/content/Robust_OFA/attacks/pgd.py", line 138, in perturb
x_adv, r_adv = perturb_iterative(
^^^^^^^^^^^^^^^^^^
File "/content/Robust_OFA/attacks/pgd.py", line 48, in perturb_iterative
outputs = predict(xvar + delta)
^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/parallel/data_parallel.py", line 191, in forward
return self.module(*inputs[0], **module_kwargs[0])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/content/Robust_OFA/ofa/classification/networks/resnets.py", line 270, in forward
x = block(x)
^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/content/Robust_OFA/ofa/utils/layers.py", line 774, in forward
residual = self.downsample(x)
^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py", line 1750, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/content/Robust_OFA/ofa/utils/layers.py", line 120, in forward
def forward(self, x):
KeyboardInterrupt
$\color{blue}{\text{Refrences}}$¶
- M. H. Ahmadilivani, M. Taheri, J. Raik, M. Daneshtalab, and M. Jenihhin, “A systematic literature review on hardware reliability assessment methods for deep neural networks,” ACM Computing Surveys, vol. 56, no. 6, pp. 1–39, 2024.
- L.-H. Hoang, M. A. Hanif, and M. Shafique, “Ft-clipact: Resilience analysis of deep neural networks and improving their fault tolerance using clipped activation,” in 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2020, pp. 1241–1246.
- B. Ghavami, M. Sadati, Z. Fang, and L. Shannon, “Fitact: Error resilient deep neural networks via fine-grained post-trainable activation functions,” in 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2022, pp. 1239–1244.
- Mousavi, Seyedhamidreza, et al. "ProAct: Progressive Training for Hybrid Clipped Activation Function to Enhance Resilience of DNNs." arXiv preprint arXiv:2406.06313 (2024).
- Mousavi, Seyedhamidreza, et al. "ProARD: Progressive Adversarial Robustness Distillation: Provide Wide Range of Robust Students " IJCNN (2025).
- M. Goldblum, L. Fowl, S. Feizi, and T. Goldstein, “Adversarially robust distillation,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, pp. 3996–4003, 2020.